Zwei Wachhunde, zwei Aufgaben: externe Verfügbarkeit und interne Metriken
UptimeRobot für externe Verfügbarkeitsprüfungen, Netdata Cloud für internes Ressourcen-Monitoring. Warum man beides braucht, was jeweils erkannt wird und wo Wettbewerber ins Bild passen.


Die meisten Monitoring-Ausfälle fallen in eine von zwei Kategorien: Der Server ist gestorben und niemand wurde benachrichtigt, oder der Server lag stundenlang im Sterben, bevor es jemand bemerkt hat. Das sind gegensätzliche Probleme, die unterschiedliche Lösungen erfordern.
Dieser Beitrag behandelt einen bewusst einfachen Stack: UptimeRobot für externes Uptime-Monitoring, Netdata Cloud für internes Ressourcen-Monitoring. Ich erkläre, warum jedes Tool für seine Aufgabe passt, wie reale Ausfallszenarien aussehen und wo Alternativen sinnvoller sein können.
Warum du zwei Arten von Monitoring brauchst
Die Ausfallszenarien sind strukturelle Gegensätze.
Wenn eine Maschine offline geht — Stromausfall, Kernel Panic, Hypervisor-Problem, ISP-Ausfall — kann sie dir keinen Alert senden. Das Monitoring-System selbst ist das, was kaputt ist. Uptime-Monitoring muss außerhalb deiner Infrastruktur leben. Der Checker und die Alert-Pipeline dürfen von dem, was deinen Dienst zum Absturz gebracht hat, nicht betroffen sein.
Wenn eine Maschine online bleibt, aber degradiert — Festplatte füllt sich, Speicherdruck, ein außer Kontrolle geratener Prozess, eine sterbende SD-Karte — willst du Frühwarnungen, bevor es kippt. Das erfordert hochauflösende, permanente Einsicht in die Interna des Servers selbst.
Keines der Tools ersetzt das andere. Ein synthetischer Uptime-Check sagt dir: „Es ist von außen kaputt, genau jetzt." Internes Ressourcen-Monitoring sagt dir: „Es ist kurz davor kaputtzugehen, und hier ist der Grund." Du brauchst beide Signale.
Externes Monitoring: UptimeRobot
Was externes Monitoring tatsächlich tut
Externes Monitoring ist synthetisch: Ein Drittanbieter-Dienst prüft deine Endpoints in festen Intervallen von außerhalb deines Netzwerks und benachrichtigt dich bei Ausfall. Die Checks reichen von einfach (TCP-Port offen, ICMP-Ping) bis nah an der echten Nutzererfahrung (HTTPS mit Keyword-Matching, DNS-Auflösung, SSL-Ablauf).
Drei Gründe, warum das extern sein muss:
- Ein ausgefallener Server kann keine Alerts senden. Ein ausgefallenes Netzwerk kann sie nicht zustellen. Die Check-Quelle muss unabhängig von deiner Ausfall-Domäne sein.
- Viele Ausfälle sind von innerhalb deines LAN unsichtbar — fehlkonfiguriertes DNS, eine kaputte Reverse-Proxy-Regel, eine Firewall-Änderung, CDN-Probleme. Externe Checks sehen deinen Dienst so, wie echte Nutzer es tun.
- Alert-Zustellung braucht ihre eigene Zuverlässigkeit. Wenn dein Benachrichtigungspfad über deine Infrastruktur läuft, fällt er genau dann aus, wenn du ihn brauchst.
Was du bei einem typischen Self-Hosted-Dienst überwachen solltest
Eine praktische Grundkonfiguration:
- HTTPS GET auf deine öffentliche URL oder einen dedizierten
/healthz-Endpoint, der bestätigt, dass die App tatsächlich läuft — nicht nur, dass nginx antwortet. - TCP-Port-Checks für alles, was kein HTTP spricht. Benutzerdefinierte Service-Ports, SSH wenn dir die Verfügbarkeit des Remote-Zugangs wichtig ist.
- Keyword-Checks auf einen String, der nur erscheint, wenn die Anwendung vollständig funktioniert. „Sign in" auf einer Login-Seite, ein bestimmtes API-Antwortfeld. Das fängt Fälle ab, in denen der Server 200 zurückgibt, aber die App kaputt ist.
- DNS-Checks zur Erkennung versehentlicher Fehlkonfigurationen oder Propagierungs-Überraschungen.
- SSL- und Domain-Ablauf — vermeidbare Ausfälle mit gravierenden Folgen. Überwache sie.
Externes Monitoring beantwortet eine Frage: „Ist es von außen kaputt, genau jetzt?" Ursachenforschung ist ein anderer Job.
Warum UptimeRobot die Standard-Empfehlung ist
Der kostenlose Plan von UptimeRobot umfasst 50 Monitore bei 5-Minuten-Intervallen mit Unterstützung für HTTP-, Port-, Ping- und Keyword-Check-Typen. Das deckt die Bedürfnisse der meisten persönlichen Projekte und kleinen Unternehmen ab, ohne einen Cent auszugeben.
Der Upgrade-Pfad ist vernünftig statt bestrafend:
- Solo-Plan: 60-Sekunden-Check-Intervalle, SSL- und Domain-Ablauf-Monitoring inklusive.
- Höhere Stufen: 30-Sekunden-Intervalle bei Enterprise, mehr Monitore, umfangreichere Integrationen, volle Statusseiten-Funktionalität (schau dir unsere eigene Statusseite an!)
- Add-ons: SMS- und Anruf-Benachrichtigungen über Credit-Pakete, wenn E-Mail und Push nicht ausreichen.
- Mobile Apps: erstklassig, mit Widgets und Push-Alerts direkt auf dem Gerät.
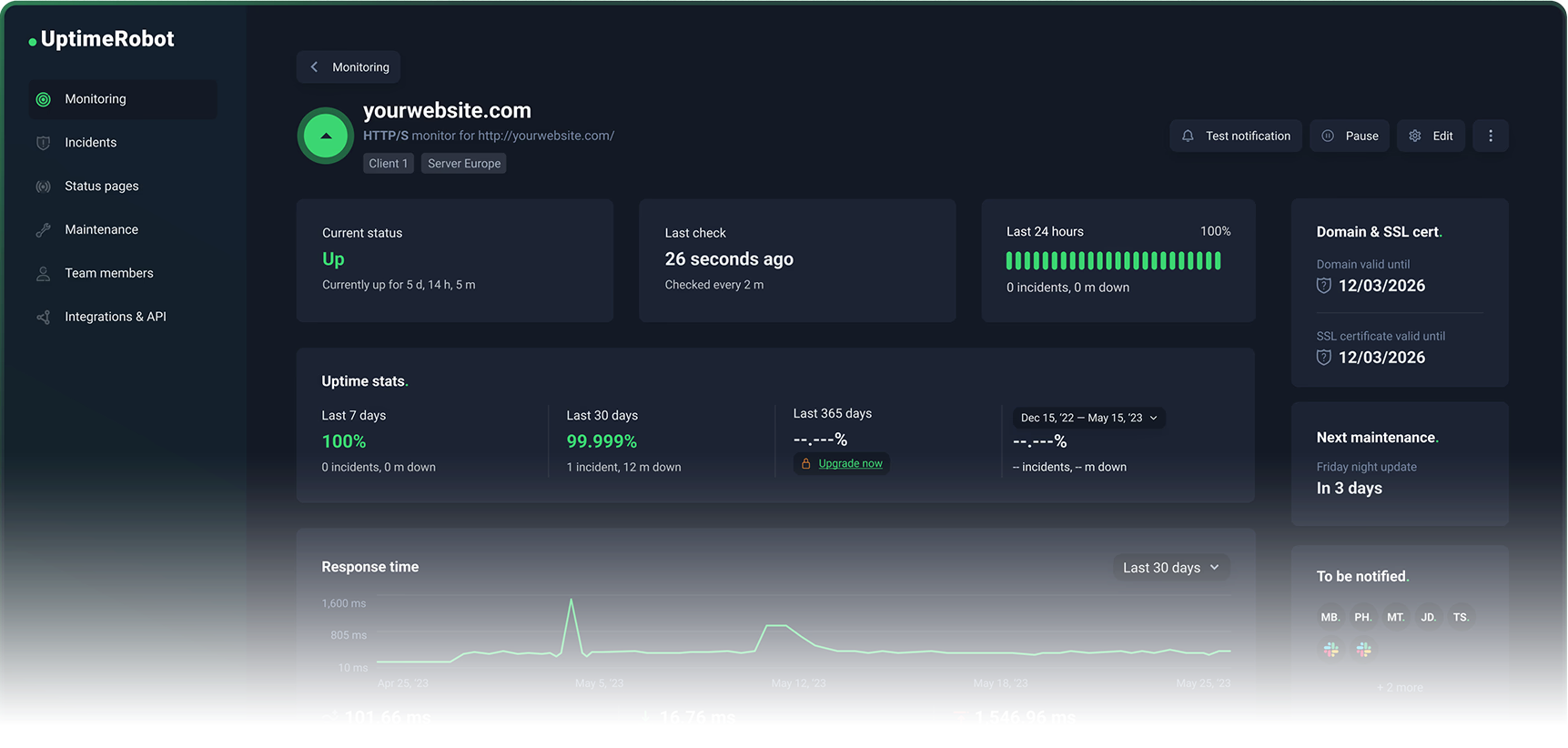
UptimeRobot bleibt fokussiert. Es macht Uptime-Monitoring. Es versucht nicht, deine Incident-Management-Plattform oder deine Observability-Suite zu werden. Du richtest es in 20 Minuten ein, vergisst es und wirst tatsächlich benachrichtigt, wenn etwas kaputtgeht.
Wo Alternativen sinnvoll sind
Better Stack (Better Uptime) ist eine Überlegung wert, wenn du umfangreicheres Incident-Management integriert mit Uptime-Monitoring möchtest. Die kostenlose Stufe umfasst 10 Monitore und eine Statusseite. Bezahlpläne bieten 30-Sekunden-Checks, Traceroute/MTR-Diagnosen und Screenshots. Der Kompromiss: breitere Plattform, mehr Komplexität, andere Preisstruktur.
StatusCake hat eine echte kostenlose Stufe und Bezahlpläne in EUR. Die kostenlose Stufe umfasst 10 Uptime-Monitore bei 5-Minuten-Intervallen. Eine echte Alternative, aber die kostenlose Stufe ist wesentlich kleiner als die 50 Monitore von UptimeRobot — oft der Unterschied zwischen „alles Wichtige überwachen" und „nur ein paar Dinge auswählen".
Checkly ist ausgezeichnet für Engineering-Teams, die synthetisches Monitoring als Code wollen, einschließlich Playwright-basierter Browser-Checks. Optimiert für Transaktionen, Traces und CI-artige Workflows. Wenn du nur Endpoints überwachen willst, ist es mehr Tool als nötig.
Pingdom ist ein langjähriges Produkt mit Uptime-Monitoring, Transaction-Monitoring und SMS-Alerting. Es bietet prominent eine kostenlose Testphase statt einer dauerhaft kostenlosen Stufe an, was dich auf eine Enterprise-orientierte Bezahlschiene setzt.
UptimeRobot gewinnt für Self-Hoster und kleine Teams, weil der kostenlose Plan groß genug ist, um echte Bedürfnisse abzudecken, der Upgrade-Pfad geradlinig ist und es beim Uptime-Problem bleibt.
Internes Monitoring: Netdata Cloud
Was internes Monitoring erkennen muss
Die meisten Self-Hosted-Ausfälle sind nicht dramatisch. Es sind langsame, langweilige Fehler, die in Ordnung aussehen, bis sie es plötzlich nicht mehr tun:
- Festplatte füllt sich: Datenbanken stoppen das Schreiben, Docker-Pulls schlagen fehl, Logs können nicht mehr geschrieben werden, das OS kann instabil werden.
- Speicherdruck: Das System thrasht, Latenzen steigen sprunghaft, und schließlich beginnt der Linux OOM-Killer Prozesse zu beenden. Von außen sieht das aus wie „meine App hat sich zufällig neugestartet."
- CPU-Sättigung: Alles funktioniert technisch, aber die Antwortzeiten steigen, bis Timeouts nachgelagerte Ausfälle auslösen.
- I/O-Engpässe: Datenbanken und Container werden langsam, Watchdogs starten Dienste neu und verbergen die eigentliche Ursache.
- Flash-Verschleiß beim Raspberry Pi: SD-Karten haben eine begrenzte Schreib-Lebensdauer. Eine wachsende Datenbank beeinträchtigt Leistung und Langlebigkeit. Home-Assistant-Nutzer kennen dieses Problem gut.
Auf modernen Linux-Systemen kann systemd-oomd vor dem Kernel-OOM eingreifen, indem es cgroup-Pressure-Stall-Informationen überwacht und Korrekturmaßnahmen ergreift. Nützlich, aber es unterstreicht den Kernpunkt: Speicherdruck ist eine erkennbare Phase. Du kannst darauf alerten, bevor Prozesse sterben.
Warum Netdata Cloud der richtige Standard ist
Der Kernwert von Netdata Cloud sind hochauflösende Dashboards, die sofort nach der Installation funktionieren. Metriken pro Sekunde, Charts für Troubleshooting konzipiert, und ein Kickstart-Installer, der dich mit einem einzigen Befehl zum Laufen bringt:
wget -O /tmp/netdata-kickstart.sh https://get.netdata.cloud/kickstart.sh && sh /tmp/netdata-kickstart.sh
Zwei architektonische Details sind für Self-Hoster wichtig:
Datenlokalität. Deine Metriken bleiben auf deiner Infrastruktur. Die Cloud-Schicht bietet Fernzugriff und zentrale Ansichten — sie zieht deine Daten nicht in ein Drittanbieter-Warehouse. Netdatas eigene Dokumentation sagt: „Deine Daten bleiben on-premises; nur Ansichten werden in die Cloud gestreamt." Für alle, die sensible Workloads betreiben oder Datenresidenz-Anforderungen unterliegen, ist das wichtig.
Sofort nützlich auf einem einzelnen Node. Anders als ein Prometheus + Grafana Stack — bei dem die Hauptarbeit im Konfigurieren des Speichers, Erstellen von Dashboards und Verdrahten des Alertings liegt — ist Netdatas Agent darauf ausgelegt, sofort auf einer einzelnen Maschine nützlich zu sein. Dashboards, Datensammlung und Alerting sind eingebaut.
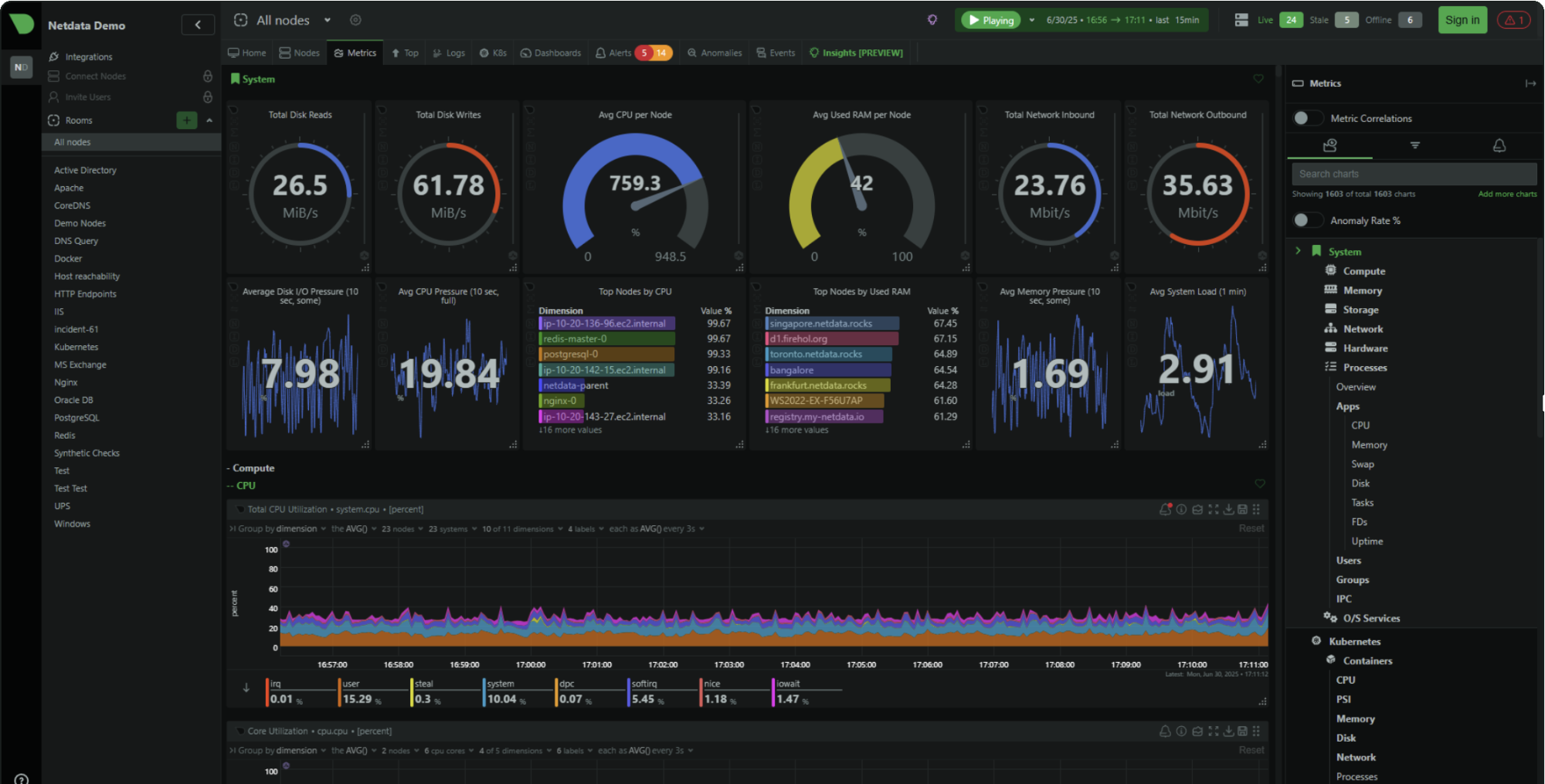
Die kostenlose Stufe (Community) unterstützt bis zu 5 verbundene Nodes mit eingeschränkten benutzerdefinierten Dashboards. Für ein Homelab, ein paar VPS-Instanzen oder ein kleines Unternehmen mit einer Handvoll Server deckt das echte Bedürfnisse ab.
Die Business-Stufe bei 4,50 $/Node/Monat (jährlich abgerechnet) bietet unbegrenzte Dashboards und Aufbewahrung, RBAC und SSO, zentralisierte Konfiguration, Enterprise-Benachrichtigungs-Integrationen und Audit-Logs. Bezahlte Features sind an betriebliche Skalierung und Team-Anforderungen gebunden, nicht an willkürliche Paywalls.
Wo Alternativen sinnvoll sind
Datadog ist die richtige Wahl, wenn du einen einzelnen Anbieter für Infrastruktur, APM, Logs, Synthetics und Security willst. Die kostenlose Stufe deckt bis zu 5 Hosts mit 1 Tag Metrik-Aufbewahrung ab. Für einen Raspberry Pi oder zwei VPS-Instanzen ist es Overkill.
Grafana Cloud hat eine wirklich nützliche kostenlose Stufe (10k aktive Metrik-Serien, 14 Tage Aufbewahrung) und Pay-as-you-go-Preise darüber hinaus. Gute Option, wenn du bereits Prometheus sprichst und ein verwaltetes Backend willst. Der Kompromiss: Du bist selbst für das Erstellen und Pflegen von Dashboards, Alert-Regeln und Instrumentierung verantwortlich.
New Relic glänzt bei tiefer Application-Telemetrie mit einem einheitlichen Datenmodell über Logs, Metriken, Traces und Events. Die kostenlose Stufe umfasst 100 GB Daten-Ingestion und einen Full-Platform-User. Eher „Observability-Plattform" als „Headless-Server-Health-Monitor".
Nagios Core und Zabbix sind nach wie vor weit verbreitet. Beide sind leistungsfähig. Beide erfordern erheblichen Konfigurationsaufwand und laufende Pflege.
Netdata gewinnt beim internen Monitoring von Headless-Servern, weil es sofortige, hochauflösende Sichtbarkeit mit minimalem Setup liefert, Daten auf deiner Infrastruktur behält und mit vorhersehbaren Pro-Node-Preisen auf Team-Features skaliert.
Warum Self-Hosting deines Monitorings meistens ein schlechter Deal ist
Die Frage ist nicht die Leistungsfähigkeit. Es geht um den operativen Aufwand im Verhältnis zum Nutzen.
Externes Monitoring: der klarste „Nicht-selbst-hosten"-Fall
Uptime Kuma ist ausgereift und unterstützt viele Monitor-Typen und Benachrichtigungen. Ich mag es. Aber Uptime Kuma selbst zu hosten bringt genau das zurück, was du vermeiden wolltest: Du musst es irgendwo betreiben, das erreichbar bleibt, wenn deine primäre Umgebung ausfällt, es gesichert und aktuell halten und die Alert-Pipeline separat pflegen.
Um externes Monitoring mit einem selbst gehosteten Tool richtig zu machen, brauchst du: mehrere geografisch verteilte Check-Standorte, eine zuverlässige Alert-Pipeline, die überlebt wenn deine Infrastruktur offline geht, Rauschunterdrückung (Retries, Bestätigungs-Checks, Wartungsfenster) und Eskalationsmanagement für Teams.
Der kostenlose Plan von UptimeRobot deckt bereits 50 Monitore ab. Wenn du bezahlst, kaufst du die betriebliche Zuverlässigkeit der Monitoring-Plattform selbst, nicht nur mehr Checks. Die Wirtschaftlichkeit spricht selten für Self-Hosting.
Internes Monitoring: Die Stack-Steuer ist real
Ein klassischer selbst gehosteter interner Stack ist Prometheus für Metriken-Speicherung und Alerting plus Grafana für Dashboards. Gute Wahl bei Skalierung oder wenn du tiefe Integration mit einer bestehenden Observability-Plattform brauchst. Auch der schnellste Weg, dein eigener Monitoring-Anbieter zu werden.
Die Stack-Steuer sind die laufenden Kosten für die Pflege dieser Infrastruktur: Storage-Konfiguration, Dashboard-Wartung, Alert-Regeln, Upgrades und das Debugging, warum dein Monitoring kaputt ist, während du versuchst etwas anderes zu debuggen.
Netdata vermeidet das für Einzelpersonen und kleine Teams, weil Dashboards, Datensammlung und Alerting out of the box funktionieren. Die SaaS-Schicht ist optional.
Das Muster, das sich in der Praxis bewährt: Nutze kostenlose verwaltete Stufen, wenn dein Ziel zuverlässiges Monitoring mit minimalem Aufwand ist. Bezahle für verwaltetes Monitoring, wenn du kürzere Intervalle, mehr Endpoints, Team-Features und ausgefeiltes Alerting brauchst. Hoste nicht selbst, sobald Monitoring komplex und geschäftskritisch wird — an dem Punkt willst du Vendor-Support, planbare Upgrades und die Garantie, dass das Monitoring oben bleibt, auch wenn du unten bist.
Reale Ausfälle, die zeigen warum das wichtig ist
Externes Monitoring erkennt Ausfälle, die von innen unsichtbar sind
Im Februar 2026 veröffentlichte Cloudflare ein Postmortem, das einen Ausfall beschrieb, bei dem bestimmte Kundenrouten per BGP zurückgezogen wurden, nachdem die Verwaltung von BYOIP-Adressen geändert wurde. Von innen betrachtet waren die Server betriebsbereit. Aus dem Internet: nicht erreichbar.
Im Oktober 2021 wurden Metas DNS-Server für den Rest des Internets unerreichbar — aufgrund von Routing-Änderungen — obwohl die Server selbst noch liefen. Metas Dienste waren „online" und gleichzeitig für jeden Nutzer auf der Welt effektiv offline.
Beides sind Ausfälle, die deine eigenen Server von innen nicht erkennen können. Externe Checks erfassen die Realität.
Eine AWS us-east-1-Störung im Oktober 2025 kaskadierte von einem latenten Defekt im automatisierten DNS-Management von DynamoDB zu breiteren Service-Auswirkungen, einschließlich fehlgeschlagener EC2-Starts. Multi-Standort-externe-Checks helfen dir zu unterscheiden zwischen „mein ISP ist kaputt", „AWS hat einen schlechten Tag" und „mein Dienst ist tatsächlich nicht erreichbar."
Internes Monitoring erkennt langsame Ausfälle, bevor sie zu Outages werden
Clerks Postmortem vom Februar 2026 ist ein Lehrbuchbeispiel: Ein ineffizienter Datenbank-Queryplan verursachte schwere Degradierung, aber ihr Failover wurde nicht ausgelöst, weil die Datenbank technisch online war. Anfragen stauten sich, 429er breiteten sich aus, und der Dienst war funktional down, während alle „Ist es oben?"-Checks grün zurückgaben.
Clerk nannte explizit „Alerting-Verbesserungen", um Queryplan-Änderungen früher zu erkennen. Die Meta-Lektion: Alerts, die nur bei vollständigen Ausfällen auslösen, kommen zu spät. Alerts basierend auf Frühindikatoren — steigende Latenz, CPU-Sättigung, wachsende Queue-Tiefe, Festplattennutzung mit Tendenz Richtung voll — verhindern, dass „degradiert" zu „tot" wird.
Bei kleineren Setups: Home-Assistant-Nutzer diskutieren regelmäßig über Datenbankwachstum auf Raspberry-Pi-Systemen und weisen darauf hin, dass Flash-Speicher eine begrenzte Schreib-Lebensdauer hat. Internes Monitoring, das Festplattennutzung und I/O-Rate trendmäßig verfolgt und bei 80% Kapazität statt bei 100% alertet, verhindert den überraschenden 2-Uhr-nachts-Ausfall, wenn die SD-Karte voll ist und nichts mehr geschrieben wird.
Die Klasse der „Zertifikat abgelaufen"-Ausfälle — Microsoft Teams hatte einen, er ist gut dokumentiert — ist vollständig vermeidbar. SSL- und Domain-Ablauf-Monitoring ist einer der Checks mit dem höchsten ROI, genau weil der Ausfall vorhersehbar ist und die Kosten der Prävention nahezu null sind.
Der Stack in der Praxis
Für die meisten persönlichen Projekte und kleinen Unternehmen:
UptimeRobot kostenloser Plan: HTTPS-Check auf deine öffentliche URL, Keyword-Check zur Bestätigung, dass die App funktioniert, TCP-Port-Check für alle Nicht-HTTP-Dienste, SSL-Ablauf-Monitoring. Fünf Minuten zum Einrichten. Fertig.
Netdata Cloud Community-Stufe: Installiere den Agent auf jedem Server mit dem Kickstart-Script. Verbinde dich mit Netdata Cloud für den Fernzugriff. Setze Alerts auf Festplattennutzung (Warnung bei 80%, kritisch bei 90%), Speicherdruck und CPU-Sättigung. Fertig.
Gesamte Einrichtungszeit: unter einer Stunde. Laufender Wartungsaufwand: nahezu null. Abdeckung: die zwei wichtigsten Ausfallszenarien, korrekt behandelt.
Wenn du über fünf Nodes hinauswächst, 60-Sekunden-Check-Intervalle brauchst oder Team-Alerting-Features benötigst — die Upgrade-Pfade sind klar und die Kosten vorhersehbar. Das ist der richtige Zeitpunkt zu bezahlen, nicht vorher.
Wo du das betreiben kannst
Die überwachten Server müssen irgendwo existieren. Hetzner bietet dir einen CX22 für 4,85 €/Monat mit 10 € Startguthaben — darauf läuft dieser Blog, und es ist eine solide Basis für alles, worauf du UptimeRobot und Netdata richten würdest. Vultr ist einen Blick wert, wenn du mehr Regionen oder einen anderen Anbieter im Mix willst — 35 $ Empfehlungsguthaben zum Start.
Wenn du OpenClaw oder AI-Agent-Workloads betreibst und die Infrastruktur nicht selbst verwalten willst, übernimmt xCloud das Hosting, damit du dich auf die Model-Schicht statt auf die Ops-Schicht konzentrieren kannst.
(Affiliate-Links — wir erhalten eine kleine Provision, wenn du dich anmeldest, ohne zusätzliche Kosten für dich.)



