Dos watchdogs, dos trabajos: disponibilidad externa y métricas internas
UptimeRobot para verificaciones externas de disponibilidad, Netdata Cloud para monitoreo interno de recursos. Por qué necesitas ambos, qué detecta cada uno y dónde encajan los competidores.


La mayoría de los fallos de monitorización caen en una de dos categorías: el servidor murió y nadie recibió una alerta, o el servidor estuvo agonizando durante horas antes de que alguien se diera cuenta. Son problemas opuestos que requieren soluciones diferentes.
Este artículo cubre un stack deliberadamente simple: UptimeRobot para monitorización externa de disponibilidad, Netdata Cloud para monitorización interna de recursos. Explicaré por qué cada herramienta encaja en su función, cómo son los modos de fallo reales y dónde tiene sentido considerar alternativas.
Por qué necesitas dos tipos de monitorización
Los modos de fallo son estructuralmente opuestos.
Cuando una máquina se cae — corte de energía, kernel panic, problema del hypervisor, caída del ISP — no puede enviarte una alerta. El propio sistema de monitorización es lo que está roto. La monitorización de disponibilidad debe vivir fuera de tu infraestructura. El comprobador y la cadena de alertas tienen que estar libres de lo que haya tumbado tu servicio.
Cuando una máquina sigue online pero se degrada — disco llenándose, presión de memoria, un proceso descontrolado, una tarjeta SD muriendo — quieres avisos tempranos antes de que se desplome. Eso requiere visibilidad de alta resolución, siempre activa, sobre los componentes internos del propio servidor.
Ninguna herramienta sustituye a la otra. Una comprobación sintética de disponibilidad te dice "está roto desde fuera, ahora mismo." La monitorización interna de recursos te dice "está a punto de romperse, y esto es por qué." Necesitas ambas señales.
Monitorización externa: UptimeRobot
Qué hace realmente la monitorización externa
La monitorización externa es sintética: un servicio de terceros comprueba tus endpoints a un intervalo fijo desde fuera de tu red y te alerta en caso de fallo. Las comprobaciones van desde lo básico (puerto TCP abierto, ping ICMP) hasta algo más cercano a la experiencia real del usuario (HTTPS con coincidencia de palabras clave, resolución DNS, caducidad SSL).
Tres razones por las que esto tiene que ser externo:
- Un servidor caído no puede enviar alertas. Una red caída no puede entregarlas. La fuente de comprobación debe ser independiente de tu dominio de fallo.
- Muchos fallos son invisibles desde dentro de tu LAN — DNS mal configurado, una regla rota del reverse proxy, un cambio en el firewall, problemas con el CDN. Las comprobaciones externas ven tu servicio como lo ven los usuarios reales.
- La entrega de alertas necesita su propia fiabilidad. Si tu cadena de notificaciones pasa por tu infraestructura, falla precisamente cuando la necesitas.
Qué monitorizar en un servicio self-hosted típico
Una línea base práctica:
- HTTPS GET a tu URL pública, o un endpoint dedicado
/healthzque confirme que la aplicación está realmente funcionando — no solo que nginx está respondiendo. - Comprobaciones de puerto TCP para cualquier cosa que no hable HTTP. Puertos de servicios personalizados, SSH si te importa la disponibilidad del acceso remoto.
- Comprobaciones de palabras clave buscando una cadena que solo aparece cuando la aplicación funciona completamente. "Sign in" en una página de login, un campo específico de respuesta de API. Esto detecta casos donde el servidor devuelve 200 pero la aplicación está rota.
- Comprobaciones DNS para detectar errores de configuración accidentales o sorpresas de propagación.
- Caducidad de SSL y dominio — fallos prevenibles con consecuencias graves. Monitorízalos.
La monitorización externa responde a una sola pregunta: "¿Está roto, desde fuera, ahora mismo?" La investigación de la causa raíz es otro trabajo.
Por qué UptimeRobot es la recomendación por defecto
El plan gratuito de UptimeRobot incluye 50 monitores a intervalos de 5 minutos con soporte para tipos de comprobación HTTP, puerto, ping y palabras clave. Eso cubre las necesidades de la mayoría de proyectos personales y pequeñas empresas sin gastar nada.
La ruta de mejora es razonable en lugar de punitiva:
- Plan Solo: intervalos de comprobación de 60 segundos, monitorización de caducidad de SSL y dominio incluida.
- Planes superiores: intervalos de 30 segundos en Enterprise, más monitores, integraciones más completas, funcionalidad completa de página de estado (¡echa un vistazo a nuestra propia página de estado!)
- Add-ons: alertas por SMS y llamada de voz mediante paquetes de créditos para cuando el email y las notificaciones push no son suficientes.
- Apps móviles: de primera clase, con widgets y alertas push en el dispositivo.
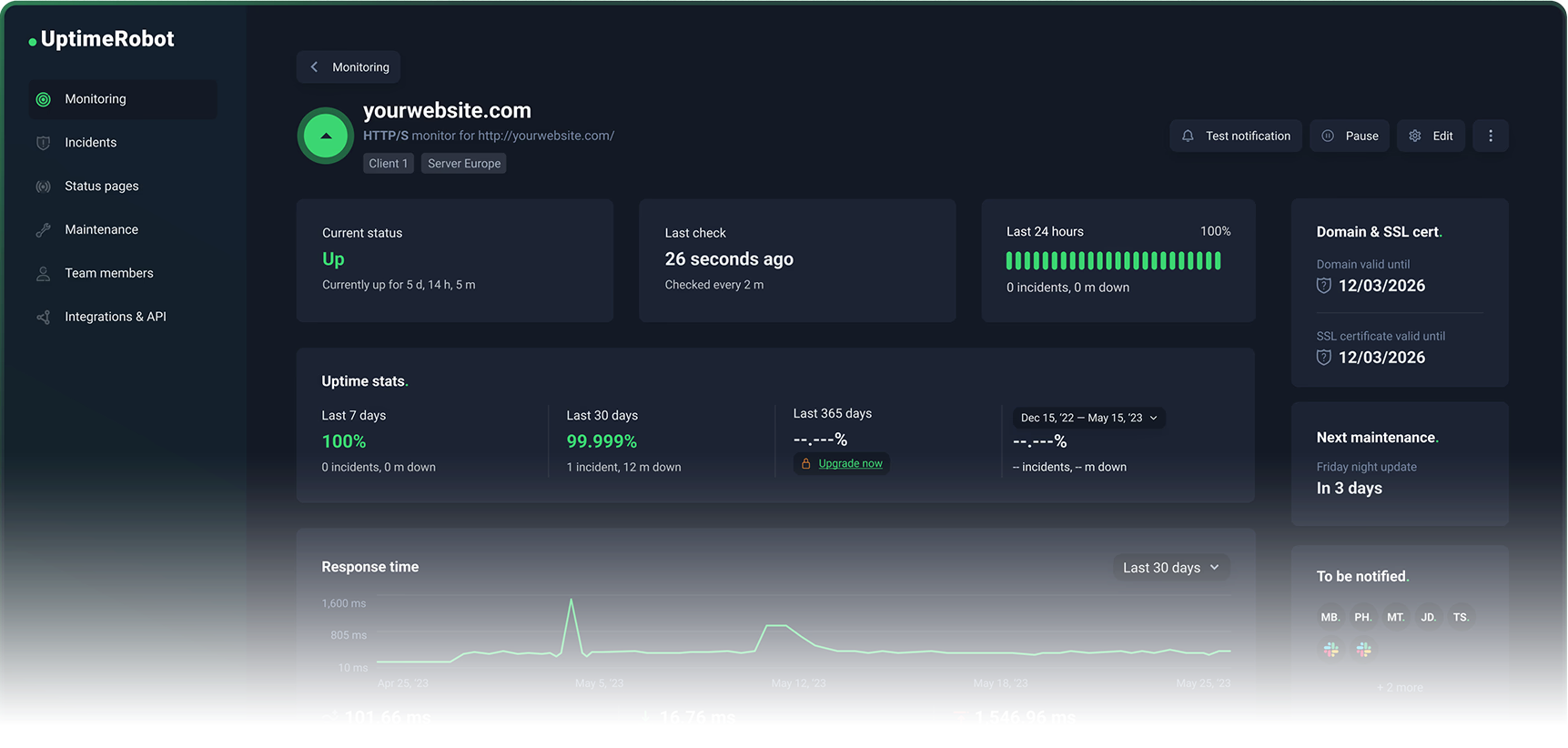
UptimeRobot se mantiene enfocado. Hace monitorización de disponibilidad. No intenta convertirse en tu plataforma de gestión de incidentes ni en tu suite de observabilidad. Lo configuras en 20 minutos, te olvidas y realmente recibes una alerta cuando algo se rompe.
Dónde tienen sentido las alternativas
Better Stack (Better Uptime) merece consideración si quieres una gestión de incidentes más completa integrada con la monitorización de disponibilidad. Su tier gratuito incluye 10 monitores y una página de estado. Los planes de pago añaden comprobaciones cada 30 segundos, diagnósticos traceroute/MTR y capturas de pantalla. La contrapartida: plataforma más amplia, más complejidad, estructura de precios diferente.
StatusCake tiene un tier gratuito legítimo y planes de pago con precios en EUR. El tier gratuito incluye 10 monitores de disponibilidad a intervalos de 5 minutos. Una alternativa real, pero su tier gratuito es materialmente más pequeño que los 50 monitores de UptimeRobot — a menudo la diferencia entre monitorizar todo lo importante y elegir solo unas pocas cosas.
Checkly es excelente para equipos de ingeniería que quieren monitorización sintética como código, incluyendo comprobaciones de navegador basadas en Playwright. Optimizado para transacciones, trazas y flujos de trabajo tipo CI. Si solo necesitas vigilar endpoints, es más herramienta de la que necesitas.
Pingdom es un producto veterano con monitorización de disponibilidad, monitorización de transacciones y alertas por SMS. Ofrece de forma prominente una prueba gratuita en lugar de un tier gratuito permanente, lo que te pone en una trayectoria de pago orientada a empresa.
UptimeRobot gana para self-hosters y equipos pequeños porque el plan gratuito es lo suficientemente amplio para cubrir necesidades reales, la ruta de mejora es directa y se mantiene enfocado en el problema de disponibilidad.
Monitorización interna: Netdata Cloud
Qué necesita detectar la monitorización interna
La mayoría de las caídas en entornos self-hosted no son dramáticas. Son fallos lentos y aburridos que parecen estar bien hasta el momento en que dejan de estarlo:
- El disco se llena: las bases de datos dejan de escribir, los pulls de Docker fallan, los logs no pueden añadirse, el sistema operativo puede volverse inestable.
- Presión de memoria: el sistema empieza a hacer thrashing, la latencia se dispara y finalmente el OOM killer de Linux empieza a matar procesos. Desde fuera esto se ve como "mi app se reinició aleatoriamente."
- Saturación de CPU: todo funciona técnicamente, pero los tiempos de respuesta suben hasta que los timeouts provocan fallos en cascada.
- Cuellos de botella de I/O: las bases de datos y los contenedores se vuelven lentos, los watchdogs reinician servicios, ocultando la causa real.
- Desgaste de flash en Raspberry Pi: las tarjetas SD tienen una vida útil de escritura finita. Una base de datos creciendo degrada el rendimiento y la longevidad. Los usuarios de Home Assistant conocen bien este problema.
En sistemas Linux modernos, systemd-oomd puede actuar antes que el OOM del kernel monitorizando la información de presión (pressure stall information) de los cgroups y tomando acciones correctivas. Útil, pero refuerza el punto central: la presión de memoria es una fase detectable. Puedes alertar sobre ella antes de que los procesos empiecen a morir.
Por qué Netdata Cloud es la opción correcta por defecto
El valor principal de Netdata Cloud son dashboards de alta resolución que funcionan inmediatamente después de la instalación. Métricas por segundo, gráficos diseñados para la resolución de problemas, y un instalador kickstart que te pone en marcha con un solo comando:
wget -O /tmp/netdata-kickstart.sh https://get.netdata.cloud/kickstart.sh && sh /tmp/netdata-kickstart.sh
Dos detalles arquitectónicos importan para los self-hosters:
Localidad de datos. Tus métricas se quedan en tu infraestructura. La capa cloud proporciona acceso remoto y vistas centralizadas — no extrae tus datos a un almacén de terceros. La propia documentación de Netdata indica "tus datos permanecen on-premises; solo las vistas se transmiten al cloud." Para cualquiera que ejecute cargas de trabajo sensibles o esté sujeto a requisitos de residencia de datos, esto importa.
Útil desde el primer día en un solo nodo. A diferencia de un stack Prometheus + Grafana — donde el trabajo pesado es configurar el almacenamiento, crear dashboards y conectar las alertas — el agente de Netdata está diseñado para ser inmediatamente útil en una sola máquina. Dashboards, recolección y alertas vienen integrados.
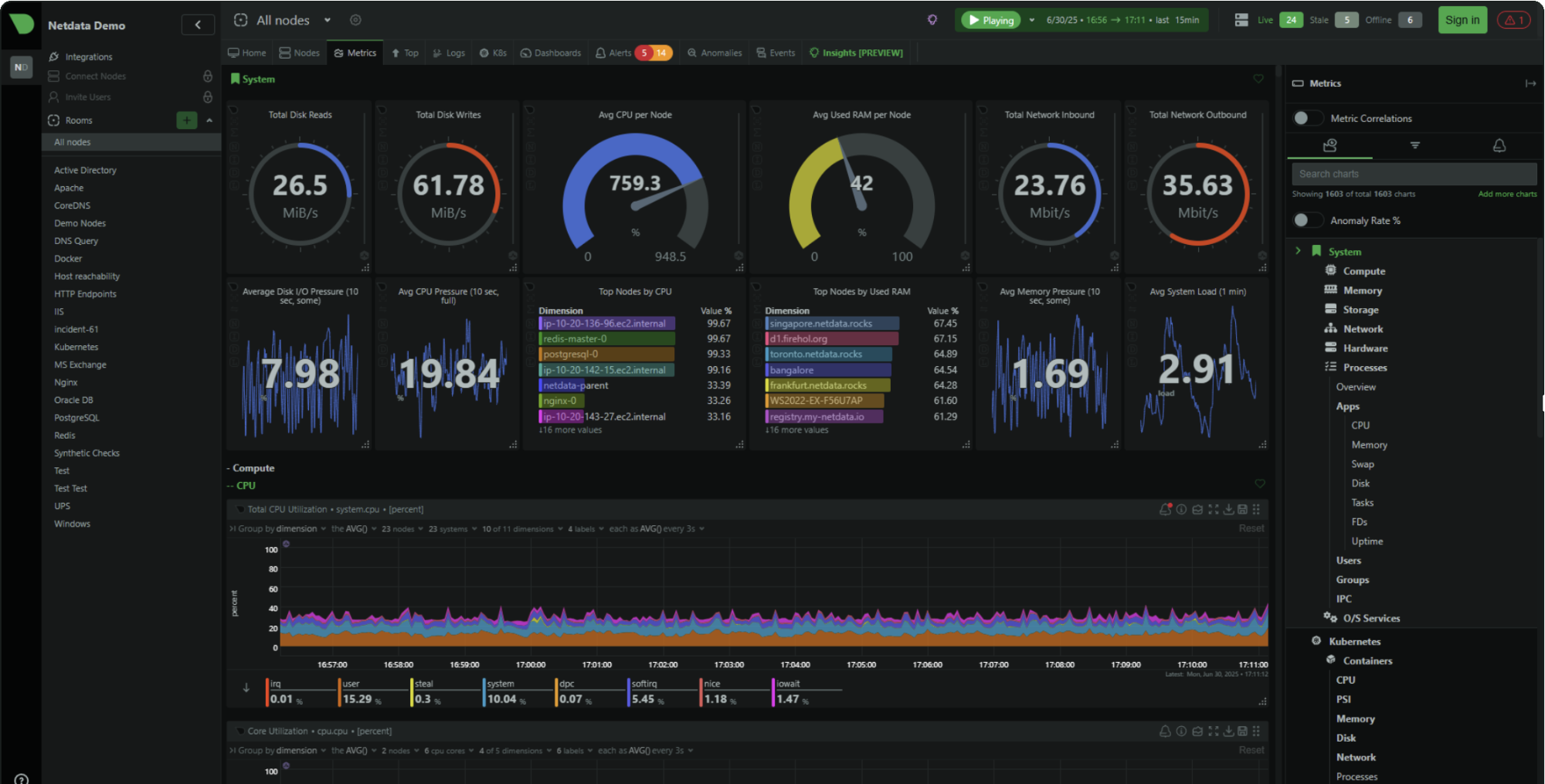
El tier gratuito (Community) soporta hasta 5 nodos conectados con dashboards personalizados limitados. Para un homelab, unas pocas instancias VPS o una pequeña empresa con un puñado de servidores, cubre las necesidades reales.
El tier Business a $4.50/nodo/mes (facturado anualmente) añade dashboards y retención ilimitados, RBAC y SSO, configuración centralizada, integraciones de notificación empresariales y logs de auditoría. Las funcionalidades de pago están vinculadas a la escala operativa y los requisitos del equipo, no a paywalls arbitrarios.
Dónde tienen sentido las alternativas
Datadog es la elección correcta cuando quieres un único proveedor para infraestructura, APM, logs, sintéticos y seguridad. Su tier gratuito cubre hasta 5 hosts con retención de métricas de 1 día. Para una Raspberry Pi o dos instancias VPS, es excesivo.
Grafana Cloud tiene un tier gratuito genuinamente útil (10k series de métricas activas, retención de 14 días) y precios de pago por uso a partir de ahí. Gran opción si ya hablas Prometheus y quieres un backend gestionado. La contrapartida: tú eres responsable de construir y mantener dashboards, reglas de alertas e instrumentación.
New Relic destaca en telemetría profunda de aplicaciones con un modelo de datos unificado entre logs, métricas, trazas y eventos. Su tier gratuito incluye 100 GB de ingesta de datos y un usuario completo de plataforma. Más "plataforma de observabilidad" que "monitor de salud de servidores headless."
Nagios Core y Zabbix siguen ampliamente desplegados. Ambos son capaces. Ambos exigen una configuración significativa y mantenimiento continuo.
Netdata gana para la monitorización interna de servidores headless porque ofrece visibilidad inmediata y de alta resolución con una configuración mínima, mantiene los datos en tu infraestructura y escala hacia funcionalidades de equipo con precios predecibles por nodo.
Por qué hacer self-hosting de tu monitorización suele ser un mal negocio
La cuestión no es la capacidad. Es la carga operativa frente al beneficio.
Monitorización externa: el caso más claro de "no hagas self-hosting"
Uptime Kuma es pulido y soporta muchos tipos de monitores y notificaciones. Me gusta. Pero hacer self-hosting de Uptime Kuma reintroduce exactamente lo que estabas intentando evitar: necesitas ejecutarlo en algún lugar que siga accesible cuando tu entorno principal esté caído, mantenerlo con Backup y actualizado, y mantener la cadena de alertas por separado.
Para hacer monitorización externa correctamente con una herramienta self-hosted, necesitas múltiples ubicaciones de comprobación geográficamente diversas, una cadena de alertas fiable que sobreviva a que tu infraestructura se caiga, control de ruido (reintentos, comprobaciones de confirmación, ventanas de mantenimiento) y gestión de escalado para equipos.
El plan gratuito de UptimeRobot ya cubre 50 monitores. Cuando pagas, estás comprando la fiabilidad operativa de la propia plataforma de monitorización, no solo más comprobaciones. Rara vez la economía favorece el self-hosting.
Monitorización interna: el impuesto del stack es real
Un stack interno self-hosted clásico es Prometheus para almacenamiento de métricas y alertas, más Grafana para dashboards. Gran elección a escala o cuando necesitas integración profunda con una plataforma de observabilidad existente. También la forma más rápida de convertirte en tu propio proveedor de monitorización.
El impuesto del stack es el coste continuo de mantener esa infraestructura: configuración de almacenamiento, mantenimiento de dashboards, reglas de alertas, actualizaciones, y depurar por qué tu monitorización se rompió mientras intentabas depurar otra cosa.
Netdata evita esto para individuos y equipos pequeños porque los dashboards, la recolección y las alertas funcionan de serie. La capa SaaS es opcional.
El patrón que se cumple en la práctica: usa tiers gratuitos gestionados cuando tu objetivo es monitorización fiable con el mínimo esfuerzo. Paga por monitorización gestionada cuando necesites intervalos más cortos, más endpoints, funcionalidades de equipo y sofisticación en las alertas. No hagas self-hosting en el momento en que la monitorización se vuelva compleja y crítica — en ese punto quieres soporte del proveedor, actualizaciones predecibles y la garantía de que la monitorización sigue funcionando incluso cuando tú estás caído.
Fallos reales que demuestran por qué esto importa
La monitorización externa detecta fallos invisibles desde dentro
En febrero de 2026, Cloudflare publicó un postmortem describiendo una caída donde ciertas rutas de clientes fueron retiradas vía BGP tras un cambio en la gestión de direcciones BYOIP. Desde dentro, los servidores estaban operativos. Desde internet, inaccesibles.
En octubre de 2021, los servidores DNS de Meta se volvieron inaccesibles para el resto de internet debido a cambios de enrutamiento — aunque los propios servidores seguían funcionando. Los servicios de Meta estaban "activos" y simultáneamente efectivamente caídos para todos los usuarios del planeta.
Ambos son fallos que tus propios servidores no pueden detectar desde dentro. Las comprobaciones externas capturan la realidad.
Una interrupción en AWS us-east-1 en octubre de 2025 se propagó desde un defecto latente en la gestión automatizada de DNS de DynamoDB hacia impactos más amplios en servicios incluyendo fallos en el lanzamiento de EC2. Las comprobaciones externas desde múltiples ubicaciones te ayudan a distinguir entre "mi ISP está roto", "AWS está teniendo un mal día" y "mi servicio está genuinamente inaccesible."
La monitorización interna detecta fallos lentos antes de que se conviertan en caídas
El postmortem de Clerk de febrero de 2026 es un ejemplo de manual: un plan de consulta de base de datos ineficiente causó una degradación severa, pero su failover no se activó porque la base de datos estaba técnicamente online. Las peticiones se encolaron, los 429 se propagaron, y el servicio estaba funcionalmente caído mientras todas las comprobaciones de "¿está activo?" devolvían verde.
Clerk mencionó explícitamente "mejoras en las alertas" para detectar cambios en los planes de consulta antes. La meta-lección: las alertas que solo se activan ante caídas completas llegan tarde. Las alertas basadas en indicadores adelantados — latencia subiendo, saturación de CPU, profundidad de cola creciendo, uso de disco tendiendo hacia lleno — evitan que "degradado" se convierta en "muerto."
En configuraciones más pequeñas: los usuarios de Home Assistant discuten regularmente sobre el crecimiento de la base de datos en sistemas Raspberry Pi, señalando que la memoria flash tiene una vida útil de escritura finita. La monitorización interna que sigue las tendencias de uso de disco y tasa de I/O, alertando al 80% de capacidad en lugar del 100%, previene la sorpresa de la caída a las 2 de la madrugada cuando la tarjeta SD se llena y todo deja de escribir.
La clase de caída por "certificado expirado" — Microsoft Teams sufrió una, está bien documentado — es completamente prevenible. La monitorización de caducidad de SSL y dominio es una de las comprobaciones con mayor retorno de inversión que puedes habilitar, precisamente porque el fallo es predecible y el coste de prevención es prácticamente cero.
El stack en la práctica
Para la mayoría de proyectos personales y pequeñas empresas:
Plan gratuito de UptimeRobot: comprobación HTTPS a tu URL pública, comprobación de palabras clave confirmando que la app funciona, comprobación de puerto TCP para cualquier servicio no HTTP, monitorización de caducidad SSL. Cinco minutos para configurar. Listo.
Tier Community de Netdata Cloud: Instala el agente en cada servidor con el script kickstart. Conéctalo a Netdata Cloud para acceso remoto. Configura alertas de uso de disco (aviso al 80%, crítico al 90%), presión de memoria y saturación de CPU. Listo.
Tiempo total de configuración: menos de una hora. Mantenimiento continuo: prácticamente cero. Cobertura: los dos modos de fallo más importantes, gestionados correctamente.
Cuando crezcas más allá de cinco nodos, o necesites intervalos de comprobación de 60 segundos, o necesites funcionalidades de alertas para equipos — las rutas de mejora son claras y los costes predecibles. Ese es el momento adecuado para pagar, no antes.
Dónde ejecutar todo esto
Necesitas que los servidores monitorizados existan en algún sitio. Hetzner te ofrece un CX22 a €4.85/mes con €10 de crédito inicial — es donde funciona este blog y una base sólida para cualquier cosa a la que apuntes UptimeRobot y Netdata. Vultr merece un vistazo si quieres más regiones o un proveedor diferente en la mezcla — $35 de crédito de referido para empezar.
Si estás ejecutando OpenClaw o cargas de trabajo de agentes de IA y no quieres gestionar la infraestructura tú mismo, xCloud se encarga del hosting para que puedas centrarte en la capa de modelos en lugar de la capa de operaciones.
(Enlaces de afiliado — nos llevamos una pequeña comisión si te registras, sin coste para ti.)



