Deux chiens de garde, deux missions : disponibilité externe et métriques internes
UptimeRobot pour les vérifications externes de disponibilité, Netdata Cloud pour la surveillance interne des ressources. Pourquoi vous avez besoin des deux, ce que chacun détecte, et où se situent les concurrents.


La plupart des échecs de monitoring tombent dans l'une de deux catégories : le serveur est mort et personne n'a été alerté, ou le serveur agonisait lentement depuis des heures avant que quiconque ne s'en aperçoive. Ce sont des problèmes opposés qui nécessitent des solutions différentes.
Cet article couvre une stack volontairement simple : UptimeRobot pour le monitoring externe de disponibilité, Netdata Cloud pour le monitoring interne des ressources. Nous expliquerons pourquoi chaque outil convient à son rôle, à quoi ressemblent les modes de défaillance réels, et dans quels cas des concurrents sont plus pertinents.
Pourquoi vous avez besoin de deux types de monitoring
Les modes de défaillance sont structurellement opposés.
Quand une machine passe hors ligne — coupure de courant, kernel panic, problème d'hyperviseur, panne FAI — elle ne peut pas vous envoyer d'alerte. Le système de monitoring lui-même est ce qui est cassé. Le monitoring de disponibilité doit vivre en dehors de votre infrastructure. Le vérificateur et la chaîne d'alerte doivent être indépendants de ce qui a mis votre service hors service.
Quand une machine reste en ligne mais se dégrade — disque qui se remplit, pression mémoire, processus emballé, carte SD mourante — vous voulez des avertissements précoces avant que tout ne bascule. Cela nécessite une visibilité haute résolution, permanente, sur les composants internes du serveur lui-même.
Aucun des deux outils ne remplace l'autre. Une vérification synthétique de disponibilité vous dit « c'est cassé vu de l'extérieur, maintenant. » Le monitoring interne des ressources vous dit « ça va bientôt casser, voici pourquoi. » Vous avez besoin des deux signaux.
Monitoring externe : UptimeRobot
Ce que fait réellement le monitoring externe
Le monitoring externe est synthétique : un service tiers vérifie vos endpoints à intervalle fixe depuis l'extérieur de votre réseau et vous alerte en cas de défaillance. Les vérifications vont du basique (port TCP ouvert, ping ICMP) au plus proche de l'expérience utilisateur réelle (HTTPS avec correspondance de mots-clés, résolution DNS, expiration SSL).
Trois raisons pour lesquelles cela doit être externe :
- Un serveur en panne ne peut pas envoyer d'alertes. Un réseau en panne ne peut pas les acheminer. La source de vérification doit être indépendante de votre domaine de défaillance.
- De nombreuses pannes sont invisibles depuis l'intérieur de votre LAN — DNS mal configuré, règle de reverse proxy cassée, changement de firewall, problèmes CDN. Les vérifications externes voient votre service comme le voient les vrais utilisateurs.
- La livraison des alertes a besoin de sa propre fiabilité. Si votre chaîne d'alerte passe par votre infrastructure, elle tombe en panne précisément quand vous en avez besoin.
Que monitorer pour un service self-hosted typique
Une base pratique :
- HTTPS GET vers votre URL publique, ou un endpoint dédié
/healthzqui confirme que l'application tourne réellement — pas seulement que nginx répond. - Vérifications de port TCP pour tout ce qui ne parle pas HTTP. Ports de services personnalisés, SSH si vous tenez à la disponibilité de l'accès distant.
- Vérifications par mot-clé pour une chaîne qui n'apparaît que lorsque l'application est pleinement fonctionnelle. « Sign in » sur une page de connexion, un champ spécifique de réponse API. Cela détecte les cas où le serveur renvoie un 200 mais l'application est cassée.
- Vérifications DNS pour détecter les erreurs de configuration accidentelles ou les surprises de propagation.
- Expiration SSL et de domaine — des défaillances évitables aux conséquences sévères. Monitorez-les.
Le monitoring externe répond à une seule question : « Est-ce cassé, vu de l'extérieur, maintenant ? » L'investigation de la cause racine est un autre travail.
Pourquoi UptimeRobot est la recommandation par défaut
Le plan gratuit d'UptimeRobot inclut 50 moniteurs à intervalles de 5 minutes avec support des types de vérification HTTP, port, ping et mot-clé. Cela couvre les besoins de la plupart des projets personnels et petites entreprises sans dépenser un centime.
Le chemin de mise à niveau est raisonnable plutôt que punitif :
- Plan Solo : intervalles de vérification de 60 secondes, monitoring d'expiration SSL et de domaine inclus.
- Plans supérieurs : intervalles de 30 secondes sur Enterprise, plus de moniteurs, intégrations plus riches, fonctionnalité complète de page de statut (consultez notre propre page de statut !)
- Add-ons : alertes SMS et appels vocaux via des packs de crédits pour quand l'email et les notifications push ne suffisent pas.
- Applications mobiles : de premier ordre, avec widgets et alertes push sur l'appareil.
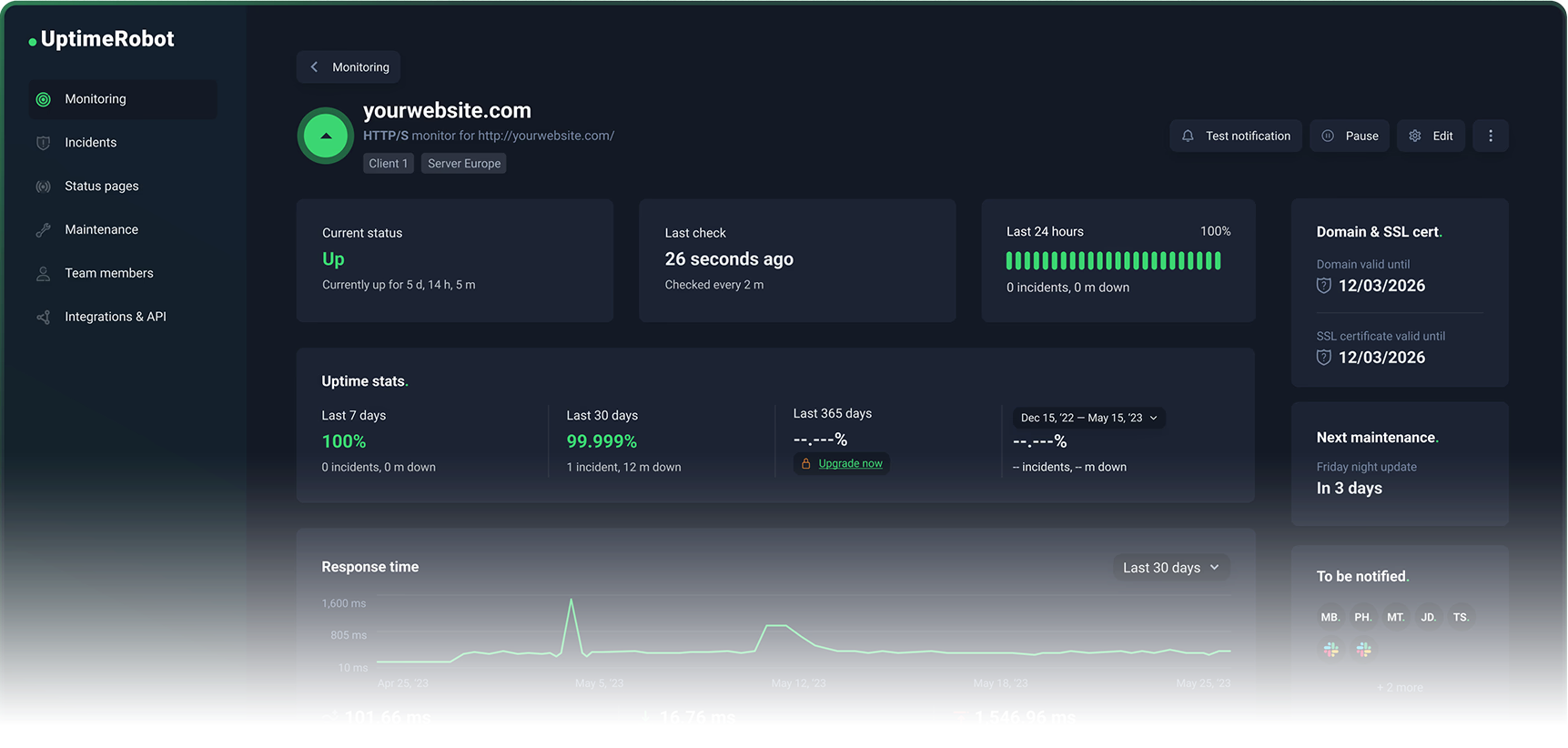
UptimeRobot reste focalisé. Il fait du monitoring de disponibilité. Il n'essaie pas de devenir votre plateforme de gestion d'incidents ou votre suite d'observabilité. Vous le configurez en 20 minutes, vous l'oubliez, et vous êtes réellement alerté quand quelque chose casse.
Quand les concurrents sont pertinents
Better Stack (Better Uptime) mérite considération si vous voulez une gestion d'incidents plus riche intégrée au monitoring de disponibilité. Son plan gratuit inclut 10 moniteurs et une page de statut. Les plans payants ajoutent des vérifications à 30 secondes, des diagnostics traceroute/MTR, et des captures d'écran. Le compromis : plateforme plus large, plus de complexité, structure tarifaire différente.
StatusCake a un vrai plan gratuit et des plans payants facturés en EUR. Le plan gratuit inclut 10 moniteurs de disponibilité à intervalles de 5 minutes. Une vraie alternative, mais son plan gratuit est matériellement plus petit que les 50 moniteurs d'UptimeRobot — souvent la différence entre monitorer tout ce qui est important et ne choisir que quelques éléments.
Checkly est excellent pour les équipes d'ingénierie qui veulent du monitoring synthétique as code, incluant des vérifications navigateur basées sur Playwright. Optimisé pour les transactions, traces et workflows de type CI. Si vous avez juste besoin de surveiller des endpoints, c'est plus d'outil que nécessaire.
Pingdom est un produit de longue date avec monitoring de disponibilité, monitoring de transactions et alertes SMS. Il propose principalement un essai gratuit plutôt qu'un plan gratuit permanent, ce qui vous place sur une trajectoire payante orientée entreprise.
UptimeRobot l'emporte pour les self-hosters et petites équipes parce que le plan gratuit est suffisamment large pour couvrir les besoins réels, le chemin de mise à niveau est direct, et il reste focalisé sur le problème de disponibilité.
Monitoring interne : Netdata Cloud
Ce que le monitoring interne doit détecter
La plupart des pannes en self-hosting ne sont pas dramatiques. Ce sont des défaillances lentes et ennuyeuses qui semblent normales jusqu'au moment où elles ne le sont plus :
- Le disque se remplit : les bases de données arrêtent d'écrire, les Docker pull échouent, les logs ne peuvent plus s'ajouter, l'OS peut devenir instable.
- Pression mémoire : le système thrash, la latence explose, et finalement le OOM killer de Linux commence à terminer des processus. Vu de l'extérieur, ça ressemble à « mon application a redémarré au hasard. »
- Saturation CPU : tout fonctionne techniquement, mais les temps de réponse grimpent jusqu'à ce que des timeouts déclenchent des défaillances en cascade.
- Goulots d'étranglement I/O : les bases de données et conteneurs deviennent lents, les watchdogs redémarrent les services, masquant la vraie cause.
- Usure du flash sur Raspberry Pi : les cartes SD ont une endurance d'écriture limitée. Une base de données en croissance dégrade les performances et la longévité. Les utilisateurs de Home Assistant connaissent bien ce problème.
Sur les systèmes Linux modernes, systemd-oomd peut agir avant le OOM du kernel en surveillant les informations de pression stall des cgroups et en prenant des mesures correctives. Utile, mais cela renforce le point central : la pression mémoire est une phase détectable. Vous pouvez alerter dessus avant que les processus ne commencent à mourir.
Pourquoi Netdata Cloud est le bon choix par défaut
La valeur fondamentale de Netdata Cloud est des dashboards haute résolution qui fonctionnent immédiatement après l'installation. Des métriques à la seconde, des graphiques conçus pour le diagnostic, et un installateur kickstart qui vous met en route avec une seule commande :
wget -O /tmp/netdata-kickstart.sh https://get.netdata.cloud/kickstart.sh && sh /tmp/netdata-kickstart.sh
Deux détails d'architecture comptent pour les self-hosters :
Localité des données. Vos métriques restent sur votre infrastructure. La couche cloud fournit l'accès distant et les vues centralisées — elle n'aspire pas vos données vers un entrepôt tiers. La propre documentation de Netdata indique « vos données restent on-premises ; seules les vues sont streamées vers le cloud. » Pour quiconque exécute des workloads sensibles ou soumis à des exigences de résidence des données, c'est important.
Utile dès le premier jour sur un seul nœud. Contrairement à une stack Prometheus + Grafana — où le gros du travail est de configurer le stockage, créer les dashboards et câbler l'alerting — l'agent Netdata est conçu pour être immédiatement utile sur une seule machine. Dashboards, collecte et alerting sont intégrés.
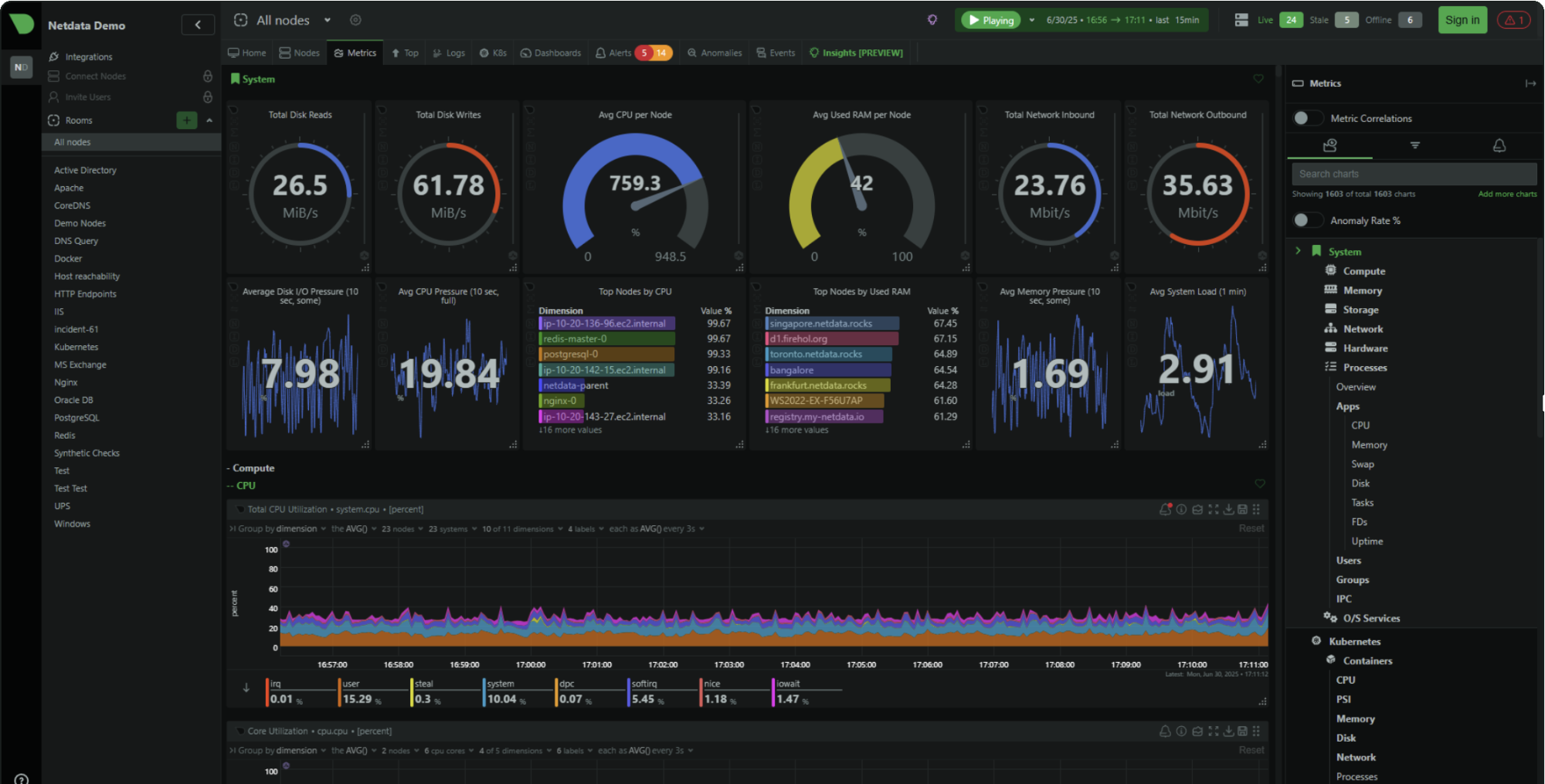
Le plan gratuit (Community) supporte jusqu'à 5 nœuds connectés avec des dashboards personnalisés limités. Pour un homelab, quelques instances VPS, ou une petite entreprise avec une poignée de serveurs, cela couvre les besoins réels.
Le plan Business à 4,50 $/nœud/mois (facturé annuellement) ajoute des dashboards et une rétention illimités, RBAC et SSO, configuration centralisée, intégrations de notification entreprise, et logs d'audit. Les fonctionnalités payantes sont liées à l'échelle opérationnelle et aux besoins d'équipe, pas à des paywalls arbitraires.
Quand les concurrents sont pertinents
Datadog est le bon choix quand vous voulez un seul fournisseur pour l'infrastructure, l'APM, les logs, le synthétique et la sécurité. Son plan gratuit couvre jusqu'à 5 hôtes avec 1 jour de rétention des métriques. Pour un Raspberry Pi ou deux instances VPS, c'est disproportionné.
Grafana Cloud a un plan gratuit véritablement utile (10k séries de métriques actives, 14 jours de rétention) et une tarification pay-as-you-go au-delà. Excellente option si vous parlez déjà Prometheus et voulez un backend managé. Le compromis : vous êtes responsable de la création et de la maintenance des dashboards, règles d'alerte et instrumentation.
New Relic brille pour la télémétrie applicative approfondie avec un modèle de données unifié pour les logs, métriques, traces et événements. Son plan gratuit inclut 100 Go d'ingestion de données et un utilisateur plateforme complète. Plus « plateforme d'observabilité » que « moniteur de santé de serveur headless. »
Nagios Core et Zabbix restent largement déployés. Les deux sont capables. Les deux exigent une configuration significative et un entretien continu.
Netdata l'emporte pour le monitoring interne de serveurs headless parce qu'il offre une visibilité immédiate et haute résolution avec un setup minimal, garde les données sur votre infrastructure, et évolue vers des fonctionnalités d'équipe avec une tarification prévisible par nœud.
Pourquoi self-hoster votre monitoring est généralement un mauvais calcul
La question n'est pas la capacité. C'est le coût opérationnel par rapport au bénéfice.
Monitoring externe : le cas le plus évident de « ne pas self-hoster »
Uptime Kuma est soigné et supporte de nombreux types de moniteurs et de notifications. Nous l'apprécions. Mais self-hoster Uptime Kuma réintroduit exactement ce que vous essayiez d'éviter : vous devez l'exécuter quelque part qui reste accessible quand votre environnement principal est en panne, le garder sauvegardé et à jour, et maintenir la chaîne d'alerte séparément.
Pour faire du monitoring externe correctement avec un outil self-hosted, vous avez besoin de multiples points de vérification géographiquement diversifiés, d'une chaîne d'alerte fiable qui survit à la panne de votre infrastructure, d'un contrôle du bruit (tentatives, vérifications de confirmation, fenêtres de maintenance), et d'une gestion d'escalade pour les équipes.
Le plan gratuit d'UptimeRobot couvre déjà 50 moniteurs. Quand vous payez, vous achetez la fiabilité opérationnelle de la plateforme de monitoring elle-même, pas juste plus de vérifications. Le calcul économique favorise rarement le self-hosting.
Monitoring interne : la taxe de stack est réelle
Une stack interne self-hosted classique est Prometheus pour le stockage de métriques et l'alerting, plus Grafana pour les dashboards. Excellent choix à grande échelle ou quand vous avez besoin d'une intégration profonde avec une plateforme d'observabilité existante. C'est aussi le moyen le plus rapide de devenir votre propre fournisseur de monitoring.
La taxe de stack est le coût continu de maintenance de cette infrastructure : configuration du stockage, maintenance des dashboards, règles d'alerting, mises à jour, et debugging de pourquoi votre monitoring est cassé pendant que vous essayiez de debugger autre chose.
Netdata évite cela pour les individus et petites équipes parce que les dashboards, la collecte et l'alerting fonctionnent directement. La couche SaaS est optionnelle.
Le schéma qui tient en pratique : utilisez les plans gratuits managés quand votre objectif est un monitoring fiable avec un minimum de travail. Payez pour du monitoring managé quand vous avez besoin d'intervalles plus courts, plus d'endpoints, de fonctionnalités d'équipe et de sophistication d'alerting. Ne self-hostez pas dès que le monitoring devient complexe et critique — à ce stade, vous voulez du support fournisseur, des mises à jour prévisibles, et la garantie que le monitoring reste debout même quand vous êtes en panne.
Des pannes réelles qui montrent pourquoi c'est important
Le monitoring externe détecte des pannes invisibles de l'intérieur
En février 2026, Cloudflare a publié un postmortem décrivant une panne où certaines routes de clients ont été retirées via BGP suite à un changement dans la gestion des adresses BYOIP. De l'intérieur, les serveurs étaient opérationnels. Depuis internet, inaccessibles.
En octobre 2021, les serveurs DNS de Meta sont devenus inaccessibles au reste d'internet à cause de changements de routage — alors que les serveurs eux-mêmes tournaient toujours. Les services de Meta étaient « up » et simultanément effectivement down pour chaque utilisateur sur terre.
Ces deux cas sont des pannes que vos propres serveurs ne peuvent pas détecter de l'intérieur. Les vérifications externes captent la réalité.
Une perturbation AWS us-east-1 en octobre 2025 s'est propagée depuis un défaut latent dans la gestion DNS automatisée de DynamoDB vers des impacts de service plus larges incluant des échecs de lancement EC2. Des vérifications externes multi-sites vous aident à distinguer « mon FAI est cassé » de « AWS passe une mauvaise journée » de « mon service est véritablement inaccessible. »
Le monitoring interne détecte les pannes lentes avant qu'elles ne deviennent des coupures
Le postmortem de Clerk de février 2026 est un cas d'école : un plan de requête de base de données inefficace a causé une dégradation sévère, mais leur failover ne s'est pas déclenché parce que la base de données était techniquement en ligne. Les requêtes s'accumulaient, les 429 se propageaient, et le service était fonctionnellement en panne tandis que toutes les vérifications « est-ce up ? » retournaient vert.
Clerk a explicitement mentionné des « améliorations d'alerting » pour détecter plus tôt les changements de plans de requête. La méta-leçon : les alertes qui ne se déclenchent que sur des pannes complètes arrivent tard. Les alertes basées sur des indicateurs avancés — latence en hausse, saturation CPU, profondeur de file en croissance, utilisation disque tendant vers le plein — empêchent « dégradé » de devenir « mort. »
Sur les installations plus petites : les utilisateurs de Home Assistant discutent régulièrement de la croissance des bases de données sur les systèmes Raspberry Pi, notant que la mémoire flash a une endurance d'écriture limitée. Un monitoring interne qui suit la tendance d'utilisation disque et le taux d'I/O, alertant à 80% de capacité plutôt qu'à 100%, prévient la panne surprise à 2h du matin quand la carte SD se remplit et que tout arrête d'écrire.
La catégorie de panne « certificat expiré » — Microsoft Teams en a subi une, c'est bien documenté — est entièrement évitable. Le monitoring d'expiration SSL et de domaine est l'une des vérifications au meilleur ROI que vous pouvez activer, précisément parce que la défaillance est prévisible et le coût de prévention est quasi nul.
La stack en pratique
Pour la plupart des projets personnels et petites entreprises :
Plan gratuit UptimeRobot : vérification HTTPS vers votre URL publique, vérification par mot-clé confirmant que l'application est fonctionnelle, vérification de port TCP pour tout service non-HTTP, monitoring d'expiration SSL. Cinq minutes à configurer. C'est fait.
Plan Community Netdata Cloud : installez l'agent sur chaque serveur avec le script kickstart. Connectez-vous à Netdata Cloud pour l'accès distant. Configurez des alertes sur l'utilisation disque (avertissement à 80%, critique à 90%), la pression mémoire et la saturation CPU. C'est fait.
Temps total de mise en place : moins d'une heure. Maintenance continue : quasi nulle. Couverture : les deux modes de défaillance les plus importants, correctement gérés.
Quand vous dépassez cinq nœuds, ou avez besoin d'intervalles de vérification de 60 secondes, ou de fonctionnalités d'alerting d'équipe — les chemins de mise à niveau sont clairs et les coûts prévisibles. C'est le bon moment pour payer, pas avant.
Où exécuter tout cela
Vous avez besoin que les serveurs monitorés existent quelque part. Hetzner vous offre un CX22 à 4,85 €/mois avec 10 € de crédit de départ — c'est ce sur quoi tourne ce blog et une base solide pour tout ce que vous pointeriez avec UptimeRobot et Netdata. Vultr vaut le coup d'œil si vous voulez plus de régions ou un fournisseur différent dans le mix — 35 $ de crédit de parrainage pour commencer.
Si vous exécutez OpenClaw ou des workloads d'agents IA et ne voulez pas gérer l'infrastructure vous-même, xCloud s'occupe de l'hébergement pour que vous puissiez vous concentrer sur la couche modèle plutôt que sur la couche ops.
(Liens affiliés — nous percevons une petite commission si vous vous inscrivez, sans coût pour vous.)



