Twee waakhonden, twee taken: externe uptime en interne metrics
UptimeRobot voor externe uptimechecks, Netdata Cloud voor interne resourcemonitoring. Waarom je beide nodig hebt, wat elk detecteert en waar concurrenten in het plaatje passen.


De meeste monitoringfouten vallen in een van twee categorieën: de server ging down en niemand werd gewaarschuwd, of de server lag uren langzaam te sterven voordat iemand het merkte. Dit zijn tegenovergestelde problemen die verschillende oplossingen vereisen.
Dit artikel behandelt een bewust eenvoudige stack: UptimeRobot voor externe uptime-monitoring, Netdata Cloud voor interne resource-monitoring. We leggen uit waarom elke tool bij zijn taak past, hoe echte storingsscenario's eruitzien, en wanneer concurrenten beter op hun plaats zijn.
Waarom je twee soorten monitoring nodig hebt
De storingsmodi zijn structureel tegengesteld.
Wanneer een machine offline gaat — stroomuitval, kernel panic, hypervisor-probleem, ISP-storing — kan hij je geen alert sturen. Het monitoringsysteem zelf is het onderdeel dat kapot is. Uptime-monitoring moet buiten je infrastructuur draaien. De checker en de alertpipeline mogen niet worden geraakt door wat je dienst ook heeft platgelegd.
Wanneer een machine online blijft maar degradeert — disk raakt vol, geheugendruk, een op hol geslagen proces, een stervende SD-kaart — wil je vroegtijdige waarschuwingen voordat het omvalt. Dat vereist hoge-resolutie, altijd-aan zichtbaarheid in de interne staat van de server zelf.
Geen van beide tools vervangt de andere. Een synthetische uptime-check vertelt je "het is kapot van buitenaf, nu." Interne resource-monitoring vertelt je "het staat op het punt kapot te gaan, dit is waarom." Je hebt beide signalen nodig.
Externe monitoring: UptimeRobot
Wat externe monitoring daadwerkelijk doet
Externe monitoring is synthetisch: een externe dienst controleert je endpoints op een vast interval van buiten je netwerk en waarschuwt je bij storingen. Checks variëren van eenvoudig (TCP-poort open, ICMP ping) tot dichter bij de echte gebruikerservaring (HTTPS met keyword-matching, DNS-resolutie, SSL-verloopdatum).
Drie redenen waarom dit extern moet zijn:
- Een server die down is kan geen alerts verzenden. Een netwerk dat down is kan ze niet afleveren. De checkbron moet onafhankelijk zijn van je storingsdomein.
- Veel storingen zijn onzichtbaar vanuit je eigen LAN — verkeerd geconfigureerde DNS, een kapotte reverse proxy-regel, een firewallwijziging, CDN-problemen. Externe checks zien je dienst zoals echte gebruikers dat doen.
- Alertaflevering heeft zijn eigen betrouwbaarheid nodig. Als je pagingpad door je eigen infrastructuur loopt, faalt het precies wanneer je het nodig hebt.
Wat te monitoren voor een typische self-hosted dienst
Een praktische basislijn:
- HTTPS GET naar je publieke URL, of een speciaal
/healthzendpoint dat bevestigt dat de app daadwerkelijk draait — niet alleen dat nginx antwoordt. - TCP-poortchecks voor alles wat geen HTTP spreekt. Custom servicepoorten, SSH als je om beschikbaarheid van remote access geeft.
- Keyword-checks op een string die alleen verschijnt wanneer de applicatie volledig functioneel is. "Sign in" op een loginpagina, een specifiek API-responseveld. Dit vangt gevallen op waarbij de server 200 retourneert maar de app kapot is.
- DNS-checks om onbedoelde misconfiguraties of propagatieverrassingen te detecteren.
- SSL- en domeinverloopdatum — vermijdbare storingen met ernstige gevolgen. Monitor ze.
Externe monitoring beantwoordt één vraag: "Is het kapot, van buitenaf, nu?" Oorzaakanalyse is een andere taak.
Waarom UptimeRobot de standaardaanbeveling is
Het gratis plan van UptimeRobot bevat 50 monitors met intervallen van 5 minuten, met ondersteuning voor HTTP-, poort-, ping- en keyword-checktypes. Dat dekt de behoeften van de meeste persoonlijke projecten en kleine bedrijven zonder iets uit te geven.
Het upgradepad is verstandig in plaats van bestraffend:
- Solo-plan: checkintervallen van 60 seconden, SSL- en domeinverloopmonitoring inbegrepen.
- Hogere tiers: intervallen van 30 seconden op Enterprise, meer monitors, rijkere integraties, volledige statuspaginafunctionaliteit (bekijk onze eigen statuspagina!)
- Add-ons: SMS- en spraakoproepalerts via kredietpakketten voor wanneer e-mail en push niet genoeg zijn.
- Mobiele apps: eersteklas, met widgets en pushmeldingen op het apparaat.
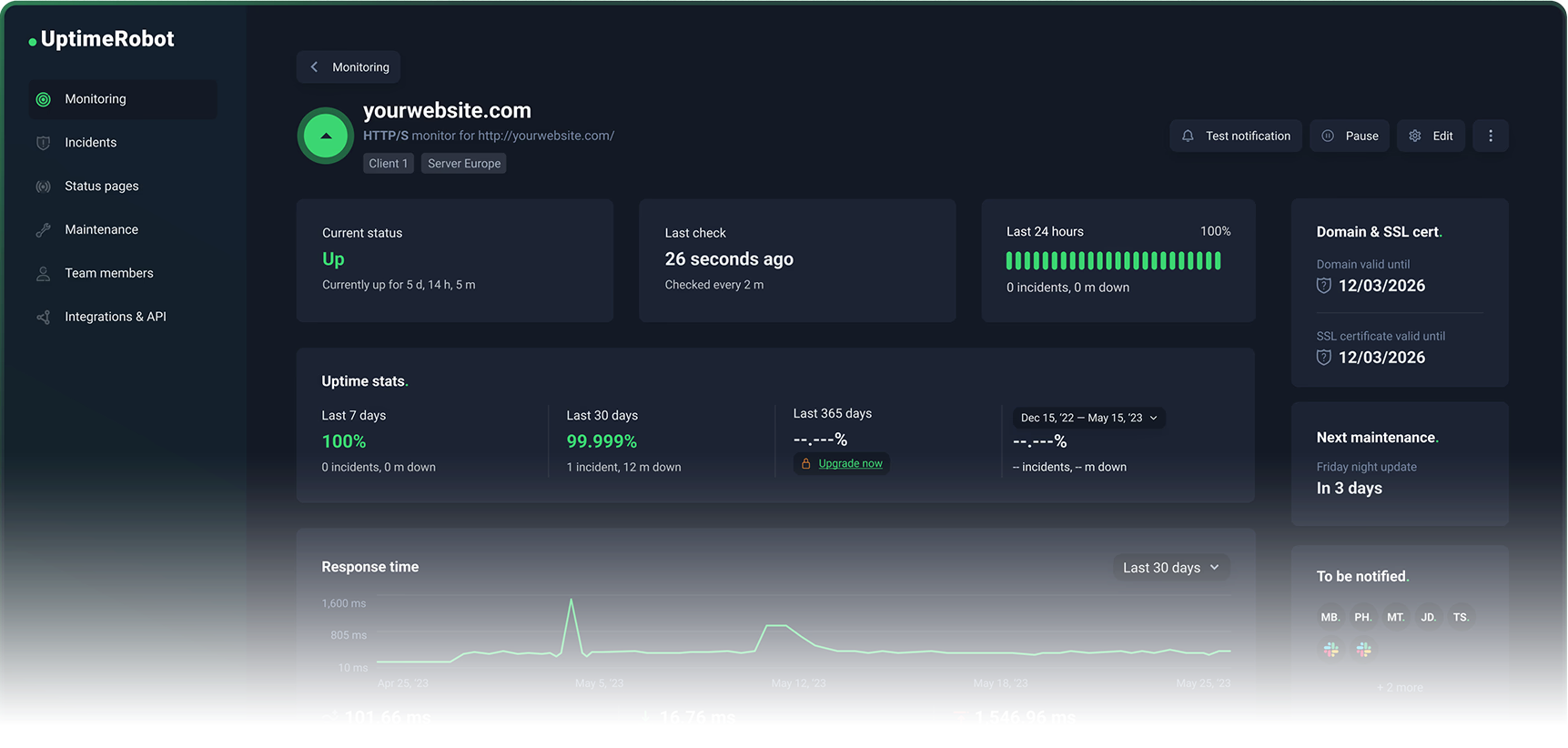
UptimeRobot blijft gefocust. Het doet uptime-monitoring. Het probeert niet je incidentmanagementplatform of je observability-suite te worden. Je stelt het in 20 minuten in, vergeet het, en wordt daadwerkelijk gepaged wanneer iets kapotgaat.
Wanneer concurrenten zinvol zijn
Better Stack (Better Uptime) is het overwegen waard als je rijker incidentmanagement geïntegreerd met uptime-monitoring wilt. De gratis tier bevat 10 monitors en een statuspagina. Betaalde plannen voegen checks van 30 seconden, traceroute/MTR-diagnoses en screenshots toe. De afweging: breder platform, meer complexiteit, andere prijsstructuur.
StatusCake heeft een legitieme gratis tier en betaalde plannen geprijsd in EUR. De gratis tier bevat 10 uptime-monitors met intervallen van 5 minuten. Een echt alternatief, maar de gratis tier is aanzienlijk kleiner dan de 50 monitors van UptimeRobot — vaak het verschil tussen alles wat belangrijk is monitoren en slechts een paar dingen uitkiezen.
Checkly is uitstekend voor engineeringteams die synthetische monitoring als code willen, inclusief Playwright-gebaseerde browserchecks. Geoptimaliseerd voor transacties, traces en CI-achtige workflows. Als je alleen endpoints wilt bewaken, is het meer tool dan je nodig hebt.
Pingdom is een gevestigd product met uptime-monitoring, transactiemonitoring en SMS-alerting. Het biedt prominent een gratis proefperiode aan in plaats van een permanente gratis tier, wat je op een enterprise-georiënteerd betaald traject zet.
UptimeRobot wint voor self-hosters en kleine teams omdat het gratis plan groot genoeg is om echte behoeften te dekken, het upgradepad eenvoudig is, en het gefocust blijft op het uptime-probleem.
Interne monitoring: Netdata Cloud
Wat interne monitoring moet opvangen
De meeste self-hosted storingen zijn niet dramatisch. Het zijn langzame, saaie storingen die er prima uitzien tot het moment dat het niet meer zo is:
- Disk raakt vol: databases stoppen met schrijven, Docker pulls mislukken, logs kunnen niet meer aangevuld worden, het OS kan instabiel worden.
- Geheugendruk: het systeem begint te thrashën, latency schiet omhoog, en uiteindelijk begint de Linux OOM killer processen te beëindigen. Van buitenaf ziet dit eruit als "mijn app herstartte willekeurig."
- CPU-saturatie: alles werkt technisch gezien, maar responstijden lopen op totdat timeouts downstream-storingen veroorzaken.
- I/O-bottlenecks: databases en containers worden traag, watchdogs herstarten services, waardoor de echte oorzaak verborgen blijft.
- Flashslijtage op Raspberry Pi: SD-kaarten hebben een beperkte schrijfduurzaamheid. Een groeiende database tast prestaties en levensduur aan. Home Assistant-gebruikers kennen dit probleem maar al te goed.
Op moderne Linux-systemen kan systemd-oomd handelen vóór de kernel OOM door cgroup pressure stall information te monitoren en corrigerende actie te ondernemen. Nuttig, maar het onderstreept het kernpunt: geheugendruk is een detecteerbare fase. Je kunt erop alerteren voordat processen beginnen te sterven.
Waarom Netdata Cloud de juiste standaard is
De kernwaarde van Netdata Cloud zijn hoge-resolutie dashboards die direct na installatie werken. Metrics per seconde, charts ontworpen voor troubleshooting, en een kickstart-installer waarmee je met één commando draait:
wget -O /tmp/netdata-kickstart.sh https://get.netdata.cloud/kickstart.sh && sh /tmp/netdata-kickstart.sh
Twee architectuurdetails zijn belangrijk voor self-hosters:
Data-localiteit. Je metrics blijven op je eigen infrastructuur. De cloudlaag biedt remote toegang en centrale overzichten — het trekt je data niet naar een extern datawarehouse. De eigen documentatie van Netdata stelt: "your data stays on-premises; only views stream to the cloud." Voor iedereen die gevoelige workloads draait of gebonden is aan dataresidentievereisten, is dit belangrijk.
Direct bruikbaar op één enkele node. In tegenstelling tot een Prometheus + Grafana stack — waar het zware werk bestaat uit opslag configureren, dashboards schrijven en alerting aansluiten — is de agent van Netdata ontworpen om direct bruikbaar te zijn op één enkele machine. Dashboards, datacollectie en alerting zitten er standaard in.
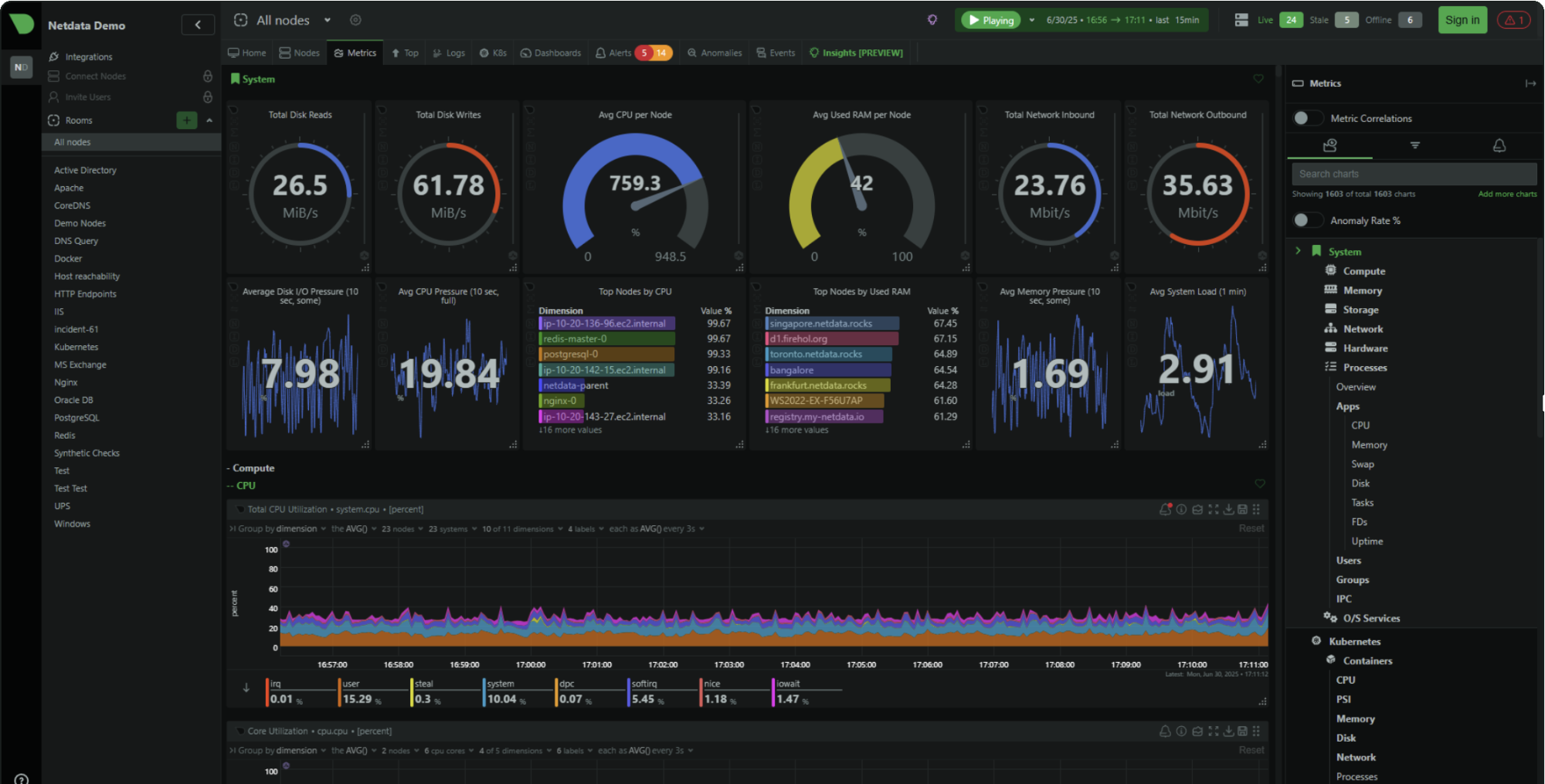
De gratis tier (Community) ondersteunt maximaal 5 verbonden nodes met beperkte aangepaste dashboards. Voor een homelab, een paar VPS-instanties of een klein bedrijf met een handvol servers dekt dat echte behoeften.
De Business-tier voor $4,50/node/maand (jaarlijks gefactureerd) voegt onbeperkte dashboards en retentie, RBAC en SSO, gecentraliseerde configuratie, enterprise-notificatie-integraties en auditlogs toe. Betaalde functies zijn gekoppeld aan operationele schaal en teamvereisten, niet aan willekeurige paywalls.
Wanneer concurrenten zinvol zijn
Datadog is de juiste keuze wanneer je één leverancier wilt voor infrastructuur, APM, logs, synthetics en security. De gratis tier dekt tot 5 hosts met 1 dag metricretentie. Voor een Raspberry Pi of twee VPS-instanties is het overkill.
Grafana Cloud heeft een oprecht bruikbare gratis tier (10k actieve metricseries, 14 dagen retentie) en pay-as-you-go-prijzen daarboven. Goede optie als je al Prometheus spreekt en een managed backend wilt. De afweging: je bent zelf verantwoordelijk voor het bouwen en onderhouden van dashboards, alertregels en instrumentatie.
New Relic blinkt uit in diepe applicatietelemetrie met een unified datamodel voor logs, metrics, traces en events. De gratis tier bevat 100 GB data-ingest en één volledige platformgebruiker. Meer "observability-platform" dan "headless server health monitor."
Nagios Core en Zabbix worden nog steeds breed ingezet. Beide zijn capabel. Beide vereisen aanzienlijke configuratie en doorlopend onderhoud.
Netdata wint voor interne monitoring van headless servers omdat het directe, hoge-resolutie zichtbaarheid levert met minimale setup, data op je eigen infrastructuur houdt, en schaalt naar teamfuncties met voorspelbare per-node-prijzen.
Waarom je monitoring self-hosten meestal een slechte deal is
De vraag is niet of het kan. Het gaat om operationele last versus voordeel.
Externe monitoring: het duidelijkste "niet self-hosten"-geval
Uptime Kuma is gepolijst en ondersteunt veel monitortypes en notificaties. We vinden het een goed project. Maar Uptime Kuma self-hosten introduceert precies wat je probeerde te vermijden: je moet het ergens draaien dat bereikbaar blijft wanneer je primaire omgeving down is, het gebackupt en bijgewerkt houden, en de alertingpipeline apart onderhouden.
Om externe monitoring goed te doen met een self-hosted tool, heb je meerdere geografisch verspreide checklocaties nodig, een betrouwbare alertingpipeline die overleeft wanneer je infrastructuur offline gaat, ruisonderdrukking (retries, bevestigingschecks, onderhoudsvensters) en escalatiebeheer voor teams.
Het gratis plan van UptimeRobot dekt al 50 monitors. Wanneer je betaalt, koop je de operationele betrouwbaarheid van het monitoringplatform zelf, niet alleen meer checks. De economische afweging valt zelden uit in het voordeel van self-hosting.
Interne monitoring: de stack tax is reëel
Een klassieke self-hosted interne stack is Prometheus voor metricsopslag en alerting, plus Grafana voor dashboards. Goede keuze op schaal of wanneer je diepe integratie met een bestaand observability-platform nodig hebt. Ook de snelste manier om je eigen monitoringleverancier te worden.
De stack tax is de doorlopende kost van het onderhouden van die infrastructuur: opslagconfiguratie, dashboardonderhoud, alertingregels, upgrades, en debuggen waarom je monitoring kapotging terwijl je iets anders probeerde te debuggen.
Netdata vermijdt dit voor individuen en kleine teams omdat dashboards, datacollectie en alerting out of the box werken. De SaaS-laag is optioneel.
Het patroon dat in de praktijk standhoudt: gebruik gratis managed tiers wanneer je doel betrouwbare monitoring met minimaal werk is. Betaal voor managed monitoring wanneer je kortere intervallen, meer endpoints, teamfuncties en geavanceerder alerting nodig hebt. Host je monitoring niet zelf zodra het complex en kritiek wordt — op dat punt wil je leveranciersondersteuning, voorspelbare upgrades, en de garantie dat monitoring blijft draaien zelfs wanneer jij down bent.
Echte storingen die laten zien waarom dit ertoe doet
Externe monitoring vangt storingen op die van binnenuit onzichtbaar zijn
In februari 2026 publiceerde Cloudflare een postmortem over een storing waarbij bepaalde klantroutes via BGP werden ingetrokken na een wijziging in het beheer van BYOIP-adressen. Van binnenuit waren de servers operationeel. Vanaf het internet: onbereikbaar.
In oktober 2021 werden de DNS-servers van Meta onbereikbaar voor de rest van het internet door routingwijzigingen — terwijl de servers zelf nog draaiden. De diensten van Meta waren "up" en tegelijkertijd effectief down voor elke gebruiker op aarde.
Beide zijn storingen die je eigen servers van binnenuit niet kunnen detecteren. Externe checks vangen de realiteit op.
Een AWS us-east-1 verstoring in oktober 2025 cascadeerde van een latent defect in DynamoDB's geautomatiseerd DNS-beheer naar bredere service-impact, inclusief EC2 launch-fouten. Multi-locatie externe checks helpen je onderscheid te maken tussen "mijn ISP is kapot," "AWS heeft een slechte dag" en "mijn dienst is echt onbereikbaar."
Interne monitoring vangt langzame storingen op voordat ze uitvallen worden
De postmortem van Clerk uit februari 2026 is een schoolvoorbeeld: een inefficiënt database query plan veroorzaakte ernstige degradatie, maar hun failover sloeg niet aan omdat de database technisch online was. Requests stapelden op, 429s verspreidden zich, en de dienst was functioneel down terwijl alle "is het up?"-checks groen teruggaven.
Clerk noemde expliciet "alerting improvements" om query plan-wijzigingen eerder te detecteren. De meta-les: alerts die alleen bij volledige uitval triggeren, komen te laat. Alerts op basis van leading indicators — latency die oploopt, CPU-saturatie, wachtrijdiepte die groeit, schijfgebruik dat richting vol trendt — voorkomen dat "gedegradeerd" verandert in "dood."
Bij kleinere setups: Home Assistant-gebruikers bespreken regelmatig databasegroei op Raspberry Pi-systemen, en wijzen erop dat flashgeheugen een beperkte schrijfduurzaamheid heeft. Interne monitoring die schijfgebruik en I/O-snelheid trending, en alert bij 80% capaciteit in plaats van 100%, voorkomt de verrassende storing om 2 uur 's nachts wanneer de SD-kaart vol raakt en alles stopt met schrijven.
De "certificaat verlopen"-klasse van storingen — Microsoft Teams had er een, het is goed gedocumenteerd — is volledig te voorkomen. SSL- en domeinverloopmonitoring is een van de checks met de hoogste ROI die je kunt inschakelen, juist omdat de storing voorspelbaar is en de preventiekosten vrijwel nul zijn.
De stack in de praktijk
Voor de meeste persoonlijke projecten en kleine bedrijven:
UptimeRobot gratis plan: HTTPS-check naar je publieke URL, keyword-check die bevestigt dat de app functioneel is, TCP-poortcheck voor eventuele niet-HTTP-services, SSL-verloopmonitoring. Vijf minuten om te configureren. Klaar.
Netdata Cloud Community-tier: Installeer de agent op elke server met het kickstart-script. Verbind met Netdata Cloud voor remote toegang. Stel alerts in op schijfgebruik (waarschuwing bij 80%, kritiek bij 90%), geheugendruk en CPU-saturatie. Klaar.
Totale setuptijd: minder dan een uur. Doorlopend onderhoud: vrijwel nul. Dekking: de twee belangrijkste storingsmodi, correct afgehandeld.
Wanneer je voorbij vijf nodes groeit, of checkintervallen van 60 seconden nodig hebt, of teamalertingfuncties nodig hebt — zijn de upgradepaden duidelijk en de kosten voorspelbaar. Dat is het juiste moment om te betalen, niet eerder.
Waar je dit draait
De servers die gemonitord worden moeten ergens bestaan. Hetzner biedt een CX22 voor €4,85/maand met €10 starttegoed — dit blog draait erop en het is een solide basis voor alles waar je UptimeRobot en Netdata op richt. Vultr is het bekijken waard als je meer regio's of een andere provider in de mix wilt — $35 referral-tegoed om mee te starten.
Als je OpenClaw of AI-agent workloads draait en de infrastructuur niet zelf wilt beheren, regelt xCloud de hosting zodat jij je kunt richten op de modellaag in plaats van de opslaag.
(Affiliatelinks — we ontvangen een kleine vergoeding als je je aanmeldt, zonder extra kosten voor jou.)



